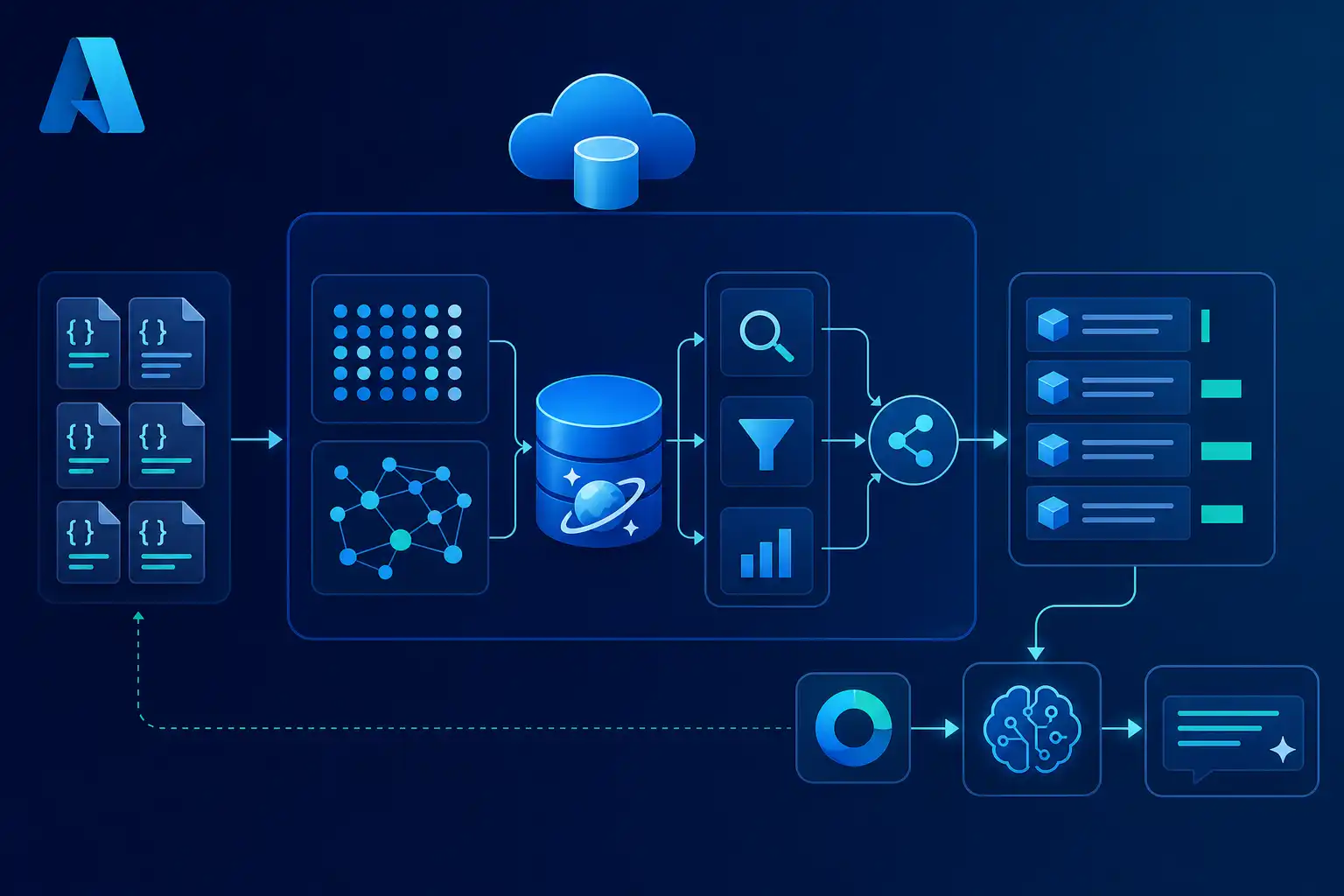
Ein typisches RAG-Problem beginnt mit einer scheinbar einfachen Frage: Ein Benutzer sucht nach „Fehler AZD-4041 nach Firmware-Update“, die Dokumentation beschreibt denselben Vorfall aber als „Device provisioning failed after image rollout“. Eine reine Vector Search findet die semantisch ähnliche Beschreibung, übersieht aber unter Umständen den exakten Fehlercode. Eine reine Full-Text-Suche findet den Fehlercode, erkennt die umschriebene Formulierung aber nicht zuverlässig.
Azure Cosmos DB for NoSQL unterstützt Azure Cosmos DB Vector Search und kann Embeddings direkt neben den ursprünglichen JSON-Dokumenten speichern. Du definierst Vektorfelder über die Container-Policy, indexierst sie im Container und kombinierst sie, sofern Full-Text-Suche für Deine API-Version und Region verfügbar ist, mit BM25-Scoring. Dadurch eignet sich Cosmos DB als RAG-Backend, wenn operative Daten bereits in Cosmos DB liegen oder wenn Du für den Start keine separate Vector-Datenbank betreiben willst.
Warum Vector Search allein für RAG oft nicht reicht
Vector Search berechnet semantische Nähe zwischen einem Query-Embedding und gespeicherten Chunk-Embeddings. Diese Methode findet Paraphrasen, Synonyme und konzeptuell ähnliche Formulierungen. Sie verliert aber Präzision bei Produktnamen, Standards, Abkürzungen, Ticket-IDs, Normen, Versionsnummern und Fehlercodes, weil ein Embedding eine Zeichenfolge nicht als harte Bedingung behandelt.
Full-Text-Suche löst das Gegenproblem. BM25 bewertet Dokumente unter anderem nach Term-Häufigkeit, inverser Dokumenthäufigkeit und Feldlänge. Azure Cosmos DB Full-Text-Suche nutzt, abhängig von Konfiguration und Sprache, Tokenisierung, Stemming, Stopwortbehandlung und BM25-Scoring. Dadurch lassen sich Begriffe wie ISO 27001, de-DE, ERR_CONNECTION_RESET oder SKU-P3 priorisieren. Für technische Kennungen solltest Du zusätzlich ein normalisiertes Code- oder Metadatenfeld erhalten, weil Tokenizer Trennzeichen wie Bindestriche und Unterstriche unterschiedlich behandeln können.
Hybrid Search verbindet beide Retrieval-Signale. Für Cosmos DB Hybrid Search RAG bedeutet das: VectorDistance liefert semantische Treffer, FullTextScore liefert keyword-basierte Relevanz, und RRF führt beide Ranglisten zusammen. Diese Architektur ist besonders nützlich für Support-Wissensdatenbanken, Produktdokumentation, Compliance-Handbücher und interne Entwicklungsdokumentation.
So funktioniert Hybrid Search in Azure Cosmos DB
Hybrid Search in Azure Cosmos DB kombiniert Vector Search mit BM25-basierter Full-Text-Suche. Die Abfrage erzeugt logisch mindestens zwei sortierte Ergebnislisten: eine Liste nach VectorDistance und eine Liste nach FullTextScore. Reciprocal Rank Fusion, kurz RRF, mischt diese Listen über die Position eines Treffers in den jeweiligen Ranglisten.
RRF verwendet nicht die ursprünglichen Score-Skalen der einzelnen Suchverfahren. Das ist wichtig, weil VectorDistance und BM25 unterschiedliche Wertebereiche besitzen. RRF belohnt Treffer, die in mehreren Listen weit oben stehen, und lässt trotzdem Treffer zu, die nur in einer Liste sehr hoch ranken. In Cosmos DB formulierst Du dieses Muster mit ORDER BY RANK RRF(...), VectorDistance und FullTextScore.
SELECT TOP 10 c.id, c.documentId, c.chunkId, c.text, c.sourceUrl
FROM c
WHERE c.tenantId = @tenantId
ORDER BY RANK RRF(
VectorDistance(c.embedding, @queryVector),
FullTextScore(c.text, @queryText)
)Das Beispiel zeigt das Kernmuster für die Kombination aus BM25, RRF und Azure Cosmos DB. In produktiven Queries ergänzt Du Filter für Tenant, Dokumenttyp, Sprache, Gültigkeit, Sicherheitsgruppen und Quellsystem. Wenn Full-Text-Treffer zwingend sein sollen, kannst Du zusätzlich mit Full-Text-Prädikaten filtern; für offene RAG-Fragen ist ein zu harter Keyword-Filter aber oft kontraproduktiv, weil er semantisch passende Paraphrasen ausschließt.
Datenmodell: Dokumente, Metadaten, Text und Embeddings zusammen speichern
Ein praktikables RAG-Modell speichert jeden Chunk als eigenes JSON-Item. Das Item enthält den Chunk-Text, den Embedding-Vektor, Metadaten und Referenzen auf das Ursprungsdokument. Diese gemeinsame Speicherung reduziert Datentransfers zwischen Datenbank, Vector Store und Retrieval-Service. Sie verhindert außerdem Inkonsistenzen, bei denen ein aktualisierter Text noch mit einem alten Embedding gesucht wird.
Empfohlene Felder pro Chunk
- id: stabiler Schlüssel wie
tenant:document:version:chunk. - documentId und documentVersion: Zuordnung zum Ursprungsdokument und kontrollierte Neuindizierung.
- chunkId und chunkRange: Reihenfolge, Zeichenbereich oder Abschnittspfad für Zitate.
- text: normalisierter Chunk-Text für Full-Text-Suche und Kontextübergabe.
- embedding und embeddingModel: Float-Array und Modellversion, damit Du später gezielt neu einbetten kannst.
- sourceUrl und sourceTitle: zitierfähige Quelle für die Antwort.
- language: Sprachcode wie
de-DEoderen-US. - acl, tenantId, validFrom, updatedAt und contentHash: Felder für Zugriffskontrolle, Mandantentrennung, Aktualität und Änderungsprüfung.
Für OCR, Dokumentanalyse, Embeddings und saubere Quellenfelder kannst Du Azure-KI-Dienste einsetzen. Einen Überblick über passende Dienste und typische Architekturbausteine findest Du in den Microsoft Azure KI Schulungen.
Den passenden Vector Index wählen: flat, quantizedFlat oder DiskANN
Azure Cosmos DB for NoSQL bietet die Vector-Index-Typen flat, quantizedFlat und diskANN. Die Auswahl beeinflusst Dimensionsgrenzen, Latenz, Speicherbedarf, Recall und Request Units. Der Index-Typ flat unterstützt bis zu 505 Dimensionen. quantizedFlat und diskANN unterstützen bis zu 4.096 Dimensionen.
| Index-Typ | Geeignet für | Wichtige Grenze | Betrieblicher Hinweis |
|---|---|---|---|
| flat | kleine Datenmengen, Tests, niedrige Dimensionen | bis 505 Dimensionen | exakte Suche, aber bei Wachstum meist weniger effizient |
| quantizedFlat | größere Embeddings und kostenbewusste Suche | bis 4.096 Dimensionen | mindestens 1.000 Vektoren einplanen und Recall testen |
| diskANN | große Korpora und niedrige Latenz bei ANN-Suche | bis 4.096 Dimensionen | mindestens 1.000 Vektoren einplanen und Filterwirkung messen |
Für quantizedFlat und DiskANN dokumentiert Microsoft ein Mindestvolumen von 1.000 Vektoren. Darunter kann Cosmos DB einen Full-Scan statt des erwarteten Vektorindexzugriffs verwenden; das erhöht in der Regel den RU-Verbrauch. Plane deshalb Testdaten oberhalb dieser Grenze und prüfe Query-Metriken, bevor Du Index-Typen vergleichst. Veröffentlichte DiskANN-Benchmarks solltest Du nur als Orientierung lesen: Latenz und Recall hängen vom Embedding-Modell, der Dimension, der Filterselektivität, der Partitionierung und dem Top-K-Wert ab.
Wenn Du Index-Policies, SDK-Zugriff und effiziente Queries in Cloud-nativen Anwendungen umsetzt, sind die Inhalte aus DP-420: Designing and Implementing Cloud-Native Applications Using Microsoft Azure Cosmos DB ein passender Cosmos-DB-Kontext für Entwicklerinnen und Entwickler.
Praxisarchitektur: Vector Policy, Full-Text-Index und Hybrid Query
Lege Vector-Embedding-Policy, Vector-Index, Full-Text-Policy und Full-Text-Index vor dem Massenupload fest. Nachträgliche Indexänderungen erzeugen Indexierungsarbeit, erhöhen den RU-Verbrauch und verzögern die Nutzbarkeit neuer Daten. Eine Container-Konfiguration beschreibt den Embedding-Pfad, die Dimensionen, die Distanzfunktion, den Vector-Index, die Spracheinstellung und den Full-Text-Pfad. Das folgende Beispiel ist bewusst gekürzt; prüfe für produktive Systeme die aktuelle Azure-Dokumentation, die API-Version und die Verfügbarkeit der Funktionen in Deiner Region.
{
"vectorEmbeddingPolicy": {
"vectorEmbeddings": [
{
"path": "/embedding",
"dataType": "float32",
"distanceFunction": "cosine",
"dimensions": 1536
}
]
},
"fullTextPolicy": {
"defaultLanguage": "de-DE",
"fullTextPaths": [
{ "path": "/text", "language": "de-DE" }
]
},
"indexingPolicy": {
"vectorIndexes": [
{ "path": "/embedding", "type": "diskANN" }
],
"fullTextIndexes": [
{ "path": "/text" }
]
}
}- Dokumente aus Confluence, SharePoint, Git-Repositories oder Produktdatenbanken extrahieren.
- Text bereinigen, Tabellen serialisieren, Überschriften erhalten und Chunks mit Abschnittsbezug erzeugen.
- Embeddings mit einem fest versionierten Embedding-Modell erstellen; die Dimensionen müssen zur Container-Policy passen.
- JSON-Item mit Text, Embedding, Metadaten, ACL-Feldern und Quellenreferenz schreiben.
- Hybrid Query mit
VectorDistance,FullTextScoreund RRF ausführen. - Top-N-Chunks mit Zitaten, Tenant-Filter und Sicherheitsfilter an das LLM übergeben.
LangChain Azure Cosmos DB in der Retrieval-Schicht
Wenn Du LangChain Azure Cosmos DB in der Retrieval-Schicht nutzen willst, prüfe zuerst, ob der verwendete Connector dieselben Funktionen abdeckt wie Deine SQL-Abfrage: VectorDistance, FullTextScore, RRF, Metadatenfilter, Paging, Retry-Handling und RU-Metriken. Ein Connector reduziert Boilerplate für Embedding-Aufruf, Retriever und Chat-History, ersetzt aber nicht eigene Messungen von Recall@k, Latenz und RU. Für LangGraph- oder Agenten-Setups solltest Du außerdem festlegen, ob Query-Rewriting, Reranking und Sicherheitsfilter im Graphen oder direkt im Retriever laufen.
Betrieb: Partitionen, Request Units, Preview-Funktionen und Monitoring
Partitionierung entscheidet darüber, ob Queries zielgerichtet oder teuer über viele Partitionen laufen. Häufige Partition-Keys sind tenantId, corpusId oder ein synthetischer Schlüssel aus Mandant und Anwendung. Wenn jede RAG-Query den Tenant kennt, senkt ein Tenant-naher Partition-Key Cross-Partition-Last. Wenn ein einzelner Mandant sehr viele Chunks besitzt, brauchst Du eine feinere Verteilung, damit Hot Partitions nicht die Latenz bestimmen.
Request Units steigen durch Full-Scans, fehlende Filter, ungeeignete Indexkonfiguration, hohe Top-K-Werte und häufige Updates großer Embedding-Felder. Aktualisiere Text und Embedding in derselben Dokumentversion, damit Retrieval und Zitierung zusammenpassen. Messe pro Query die RU, P50/P95-Latenz, Trefferanzahl, Fehlerrate, verwendete Partitionen und Änderungen an Index-Policies.
Full-Text-Suche, mehrsprachige Analyse und Hybrid-Search-Funktionen können je nach Azure-Region, API-Version und Freischaltung unterschiedlich verfügbar sein. Prüfe den aktuellen Produktstatus, bevor Du sie produktiv einplanst. Für deutsche Inhalte solltest Du zusammengesetzte Substantive, Abkürzungen, Produktcodes und englisch-deutsche Mischtexte separat testen, weil diese Fälle die Tokenisierung und das Ranking stärker belasten als einfache Fließtexte.
Für Datenmodellierung, Queries, Indexing, Performance, Sicherheit, Backup und betriebliche Verfahren ist solides Cosmos-DB-Wissen nötig. Teams, die RAG-Betrieb mit Datenbank-Grundlagen verbinden möchten, können die Azure Cosmos DB - Compact Training Schulung nutzen. Ergänzend findest Du thematisch passende Datenbank-Schulungen.
Retrieval-Qualität messen, bevor Du Antworten freigibst
Bei RAG lassen sich zwei Fehlerarten getrennt messen: Der Retriever liefert falsche Chunks, oder das LLM nutzt richtige Chunks falsch. Trenne deshalb Retrieval-Tests von Antworttests. Zuerst prüfst Du, ob die erwarteten Quellen in den Top-k-Treffern auftauchen; erst danach bewertest Du Tonalität, Vollständigkeit und Quellenbezug der generierten Antwort.
Erstelle Golden Queries aus echten Benutzerfragen. Die Sammlung sollte Produktnamen, Fehlercodes, Abkürzungen, Normen, mehrsprachige Begriffe, alte und neue Bezeichnungen sowie Fragen mit negativen Bedingungen enthalten. Speichere pro Golden Query die erwarteten Quellen, akzeptable Alternativquellen und typische Falsch-Treffer.
- Recall@k: Erscheinen die erwarteten Chunks in Top 5 oder Top 10?
- Precision@k: Wie viele Top-Treffer gehören fachlich zur Frage?
- MRR oder nDCG: Wie weit oben stehen die besten Treffer, wenn mehrere Kandidaten korrekt sind?
- Source coverage: Decken die Treffer alle benötigten Quelldokumente ab?
- Citation quality: Verweisen Antwortzitate auf den richtigen Abschnitt?
- Hallucination failures: Erfindet das LLM Aussagen, obwohl die Chunks keine Grundlage liefern?
Wiederhole die Tests nach jeder Änderung an Chunk-Größe, Overlap, Embedding-Modell, Vector-Index, Full-Text-Policy, RRF-Gewichtung oder Filterlogik. Protokolliere für jeden Testlauf dieselben Query-IDs, Indexeinstellungen, Top-K-Werte, RU-Werte und Latenzperzentile, sonst vergleichst Du später nicht die Retrieval-Qualität, sondern wechselnde Rahmenbedingungen. Für vertiefte Arbeit an Embeddings, Hybrid Search, Reranking, Citations, Grounding und Evaluation passt der Large Language Models Advanced Course: RAG, Adaptation, and Training. Weitere Inhalte findest Du unter KI Engineering & LLMs.
Entscheidungshilfe: Wann Cosmos DB reicht und wann ein Suchdienst sinnvoll ist
Cosmos DB reicht häufig aus
- Du speicherst operative JSON-Daten bereits in Cosmos DB.
- Text, Metadaten und Embeddings ändern sich häufig.
- Kurze Aktualisierungszeiten sind wichtiger als ein separates Index-Pipeline-System.
- Du willst weniger Dienste, weniger Datenkopien und ein einheitliches Berechtigungsmodell.
- Deine Evaluation zeigt ausreichenden Recall, stabile Zitate und akzeptable Latenz.
Ein Search-Service ist zu prüfen
- Du brauchst spezialisierte Suchfunktionen, die über Hybrid Search hinausgehen.
- Redaktionelle Suchabstimmung, Synonym-Management und Such-UX dominieren die Anforderungen.
- Indexierungspipelines sind fachlich komplexer als die operative JSON-Speicherung.
- Separate Skalierung von Suchindex und Datenbank senkt Kosten oder Latenz.
- Dein Team besitzt mehr Erfahrung mit Suchrelevanz als mit Cosmos-DB-Query-Tuning.
Triff die Entscheidung anhand von Datenfrische, Betriebsaufwand, Retrieval-Qualität, Latenz, RU-Kosten und Team-Erfahrung. Starte mit einer Cosmos-DB-Implementierung, wenn Deine Daten ohnehin als JSON-Dokumente vorliegen und häufig aktualisiert werden. Prüfe einen zusätzlichen Suchdienst wie Azure AI Search erst dann, wenn Deine Golden Queries messbar zeigen, dass spezialisierte Suchfunktionen die Antwortqualität verbessern oder die Betriebskosten senken.
Nächster Schritt für Dein RAG-Backend
Baue zuerst einen kleinen, messbaren Prototyp: einen Container, eine Vector-Embedding-Policy, eine Full-Text-Policy, einen passenden Index, mindestens 1.000 Chunks für quantizedFlat oder diskANN, 25 bis 50 Golden Queries und ein Dashboard für RU, Latenz und Trefferqualität. Wenn Cosmos DB Hybrid Search RAG die erwarteten Quellen stabil findet, hast Du ein RAG-Backend ohne zusätzliche Vector-Datenbank. Wenn Recall, Relevanz oder Such-UX nicht ausreichen, besitzt Du mit denselben Golden Queries die Entscheidungsgrundlage für einen zusätzlichen Suchdienst.