
Gescannte Dokumente bestehen zunächst nur aus einem Bild. Der Inhalt sieht zwar wie Text aus, lässt sich aber weder durchsuchen noch markieren oder korrigieren. Mit Adobe Acrobat kann daraus über die OCR-Texterkennung ein digitales PDF entstehen, in dem Wörter gefunden, kopiert und bei richtiger Einstellung sogar direkt bearbeitet werden können.
Der entscheidende Punkt liegt in den OCR-Einstellungen: Acrobat kann entweder eine unsichtbare Textschicht über das Scanbild legen oder das Dokument so interpretieren, dass bearbeitbarer Text und Bilder entstehen. In dieser Anleitung zeigen wir Schritt für Schritt, wie gescannte PDFs mit Adobe Acrobat Pro in bearbeitbare Dokumente umgewandelt werden, welche Spracheinstellung wichtig ist und warum eine reine Texterkennung nicht automatisch bedeutet, dass der sichtbare Text im PDF verändert werden kann.
Wenn du regelmäßig mit PDFs, digitalen Formularen, Scans, Archivdokumenten oder Korrekturläufen arbeitest, lohnt sich zusätzlich ein Blick in unsere Adobe Acrobat Schulungen. Dort werden OCR, PDF-Bearbeitung, Formularfunktionen, Barrierefreiheit und professionelle Dokumentenworkflows praxisnah vertieft.
Ausgangssituation: Ein gescanntes Dokument
Im Beispiel liegt ein gescanntes Dokument vor. Um die Leistungsfähigkeit der Texterkennung sichtbar zu machen, wurde der Scan bewusst mit niedriger Auflösung erstellt. Dadurch sind pixelige Artefakte an den Buchstaben erkennbar. Genau solche Scans kommen in der Praxis häufig vor, etwa bei alten Verträgen, eingescannten Briefen, Archivunterlagen oder Dokumenten, die per E-Mail als Bild-PDF verschickt wurden.

Solange keine OCR durchgeführt wurde, erkennt Acrobat den Inhalt nur als Bild. Ein Klick in das Dokument markiert deshalb keine Wörter oder Absätze. Auch die Suche im PDF findet keine Textstellen, weil noch keine auswertbaren Zeichen vorhanden sind.
Texterkennung in Adobe Acrobat starten
Per einfachem Klick in das Dokument erscheint in aktuellen Acrobat-Versionen häufig eine Symbolleiste mit dem Befehl Text erkennen. Diese Funktion startet die OCR-Texterkennung für das geöffnete PDF.
Alternativ befindet sich die Funktion unter Alle Tools im Bereich Scan & OCR. Dieser Weg ist besonders hilfreich, wenn die automatische Symbolleiste nicht angezeigt wird oder wenn mit einer älteren Acrobat-Oberfläche gearbeitet wird.
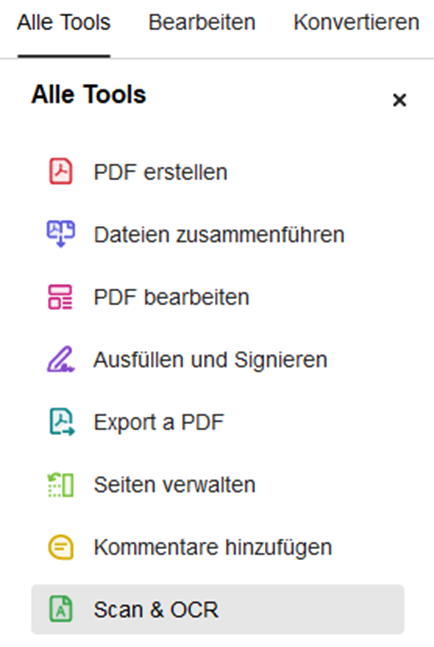
Sprache und OCR-Einstellungen richtig wählen
Nach dem Öffnen von Scan & OCR erscheint das kleine Fenster mit der blauen Schaltfläche Text erkennen. Diese Schaltfläche sollte nicht sofort angeklickt werden. Für ein gutes Ergebnis ist zuerst die richtige Sprache einzustellen. Bei deutschsprachigen Dokumenten sollte also Deutsch gewählt werden, damit Acrobat Umlaute, Trennungen, Satzzeichen und typische Wortformen besser interpretiert.
Falls das Fenster nicht automatisch erscheint, hilft ein Klick auf In dieser Datei. Anschließend können die Einstellungen für die Texterkennung angepasst werden.
Wichtig zu wissen: Bei der herkömmlichen Texterkennung bleibt das originale gescannte Bild im Hintergrund erhalten. Acrobat legt lediglich eine unsichtbare Textschicht darüber. Diese Textschicht macht das PDF durchsuchbar und ermöglicht das Markieren oder Kopieren von Wörtern. Der sichtbare Scan bleibt jedoch weiterhin ein Bild. Der Text kann dann zwar für die Suche korrigiert werden, aber nicht wie normal gesetzter PDF-Text für Leserinnen und Leser bearbeitet werden.
Damit der Text tatsächlich im PDF geändert werden kann, muss in den OCR-Einstellungen die Ausgabe so gewählt werden, dass Acrobat bearbeitbaren Text und Bilder erzeugt. Je nach Acrobat-Version kann die Bezeichnung leicht abweichen. Entscheidend ist, dass nicht nur eine durchsuchbare Bildversion erstellt wird, sondern ein editierbares PDF-Dokument entsteht.

Vom Scan zum bearbeitbaren PDF
Nachdem Sprache und Ausgabeformat eingestellt sind, wird die OCR mit Text erkennen gestartet. Acrobat analysiert die Seiten, erkennt Buchstaben, Wörter und Textbereiche und baut daraus eine bearbeitbare Struktur auf. Je nach Länge des Dokuments, Scanqualität und Rechnerleistung kann dieser Vorgang einige Sekunden bis mehrere Minuten dauern.
Nach der Texterkennung lässt sich das Ergebnis über das Werkzeug PDF bearbeiten prüfen. Nun können Textstellen angeklickt und geändert werden. Acrobat versucht, Schriftart, Schriftgröße, Laufweite und Position an das gescannte Original anzupassen. Bei sehr schlechten Scans, schiefen Vorlagen, handschriftlichen Ergänzungen oder ungewöhnlichen Schriftarten sind Nachkorrekturen fast immer erforderlich.
- Die richtige Sprache verbessert die Erkennungsrate deutlich
- Eine gute Scanauflösung reduziert OCR-Fehler
- Gerade ausgerichtete Seiten erleichtern die Texterkennung
- Bearbeitbarer Text ist nicht identisch mit einer unsichtbaren Suchtext-Schicht
- Nach der OCR sollte das Dokument immer sorgfältig geprüft werden
Warum der Unterschied zwischen durchsuchbar und bearbeitbar wichtig ist
In vielen Workflows reicht ein durchsuchbares PDF völlig aus, zum Beispiel für digitale Archive, Dokumentenmanagement oder die Volltextsuche in Vertragsunterlagen. Sobald Inhalte jedoch korrigiert, aktualisiert oder an ein neues Layout angepasst werden sollen, wird ein bearbeitbares PDF benötigt.
Die OCR-Funktion in Acrobat löst beide Anforderungen, aber nicht mit derselben Einstellung. Deshalb ist es sinnvoll, vor dem Start der Texterkennung zu entscheiden, welches Ziel erreicht werden soll:
- Durchsuchbares PDF: Das Scanbild bleibt erhalten, Acrobat legt eine unsichtbare Textschicht darüber
- Bearbeitbares PDF: Acrobat interpretiert Textbereiche und Bilder neu, sodass Inhalte mit dem Bearbeiten-Werkzeug verändert werden können
- Export in Word oder andere Formate: Sinnvoll, wenn längere Textpassagen redaktionell überarbeitet oder neu formatiert werden sollen
Für professionelle PDF-Workflows ist diese Unterscheidung zentral. Wer regelmäßig gescannte Dokumente optimiert, Formulare vorbereitet oder PDF-Dateien für Kolleginnen, Kunden oder Behörden aufbereitet, sollte die OCR-Einstellungen in Acrobat sicher beherrschen.
Praxistipps für bessere OCR-Ergebnisse
- Scans möglichst gerade ausrichten, bevor die Texterkennung gestartet wird
- Für gedruckte Dokumente eine ausreichende Scanauflösung verwenden
- Bei mehrsprachigen Dokumenten die wichtigste Dokumentsprache bewusst auswählen
- Starke Komprimierung vermeiden, da Buchstaben sonst unsauber erkannt werden
- Nach der OCR Namen, Zahlen, Beträge und Fachbegriffe besonders sorgfältig prüfen
- Bei umfangreichen Änderungen gegebenenfalls den Export nach Word nutzen
Adobe Acrobat bietet weit mehr als nur das Anzeigen von PDFs. In der täglichen Arbeit gehören OCR, PDF-Bearbeitung, Kommentieren, Schützen, Kombinieren, Exportieren und Formularfunktionen eng zusammen. In den Acrobat Trainings bei cmt wird genau dieser Praxisbezug vermittelt: nachvollziehbar, anwendungsorientiert und mit typischen Aufgaben aus dem Büro- und Projektalltag.