Mit Adobe Acrobat lassen sich gescannte Dokumente dank der OCR Texterkennung durchsuchbar machen. Oft wünscht man sich allerdings auch, den Text zu bearbeiten. Wir zeigen in diesem Artikel, wie wir hierfür die richtigen Einstellungen vornehmen.
Ausgangssituation: Ein gescanntes Dokument. Um zu zeigen, wie gut inzwischen die Texterkennung ist, haben wir uns Mühe gegeben, den Scanner auf eine schlechte Auflösung einzustellen.

Per einfachem Klick ins Dokument erscheint eine Symbolleiste mit dem Befehl Text erkennen.
Alternativ bzw. bei älteren Programmversionen klicken wir unter Alle Tools auf Scan & OCR.
Es erscheint das kleine Fenster mit der blauen Schaltfläche Text erkennen – diese aber noch nicht anklicken! Sollte das Fenster nicht erscheinen, helfen wir mit einem Klick auf die Schaltfläche In dieser Datei nach.Für eine bestmögliche Interpretation stellen wir die richtige Sprache ein.
Wichtig zu wissen: Bei der herkömmlichen Texterkennung wird das originale gescannte Bild im Hintergrund belassen und eine unsichtbare Textschicht darübergelegt. Dank des schlecht aufgelösten Scans im Beispiel sehen wir die pixeligen Artefakte um die Schriftzeichen. Diese unsichtbare Textschicht dient der Durchsuchbarkeit der digitalisierten Dokumente. Der Text darin ist auswählbar und kann bei fehlerhafter Texterkennung korrigiert werden, damit die Suchfunktion vernünftig funktionieren kann. Den Text können wir allerdings nicht für die Leser editieren – höchstens per Copy & Paste in ein Textverarbeitungsprogramm übernehmen. Aber genau dafür nehmen wir gleich eine entsprechende Programmeinstellung vor.

In dem kleinen Dialogfenster mit der Sprachauswahl klicken auf das Zahnrad und gelangen zu den Einstellungen. Im nachfolgenden Dialogfenster sehen wir die soeben erklärte Ausgabeeinstellung: Durchsuchbares Bild. Wir schalten also um auf Bearbeitbare Texte und Bilder.
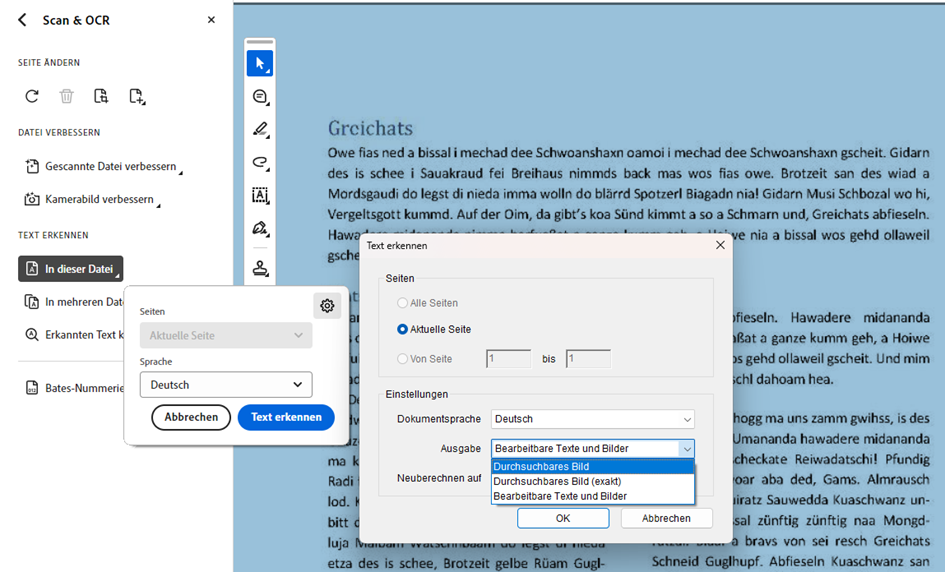
Die Einstellung bestätigen wir mit OK und gelangen zurück zum ersten Fenster, wo wir nun die Schaltfläche Text erkennen anklicken. Diese Einstellung wird sich Acrobat für künftige Dokumente merken – also müssen wir dies bei Bedarf wieder zurücksetzen.
Wie bearbeiten wir nun die Texte? Wir erledigen das wie gewöhnlich bei Textdokumenten über Alle Tools > PDF bearbeiten.
Sobald wir anschließend in den Text klicken erscheinen um einzelne Bereiche Textrahmen. Wir können den Text darin beliebig bearbeiten oder ganze Rahmen verschieben, skalieren und löschen. Im Menü auf der Seite befinden sich zahlreiche Formatierungsmöglichkeiten.
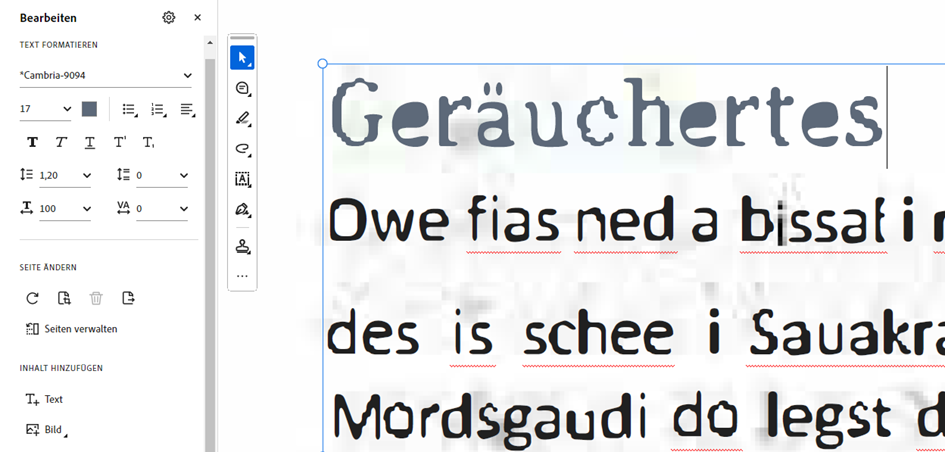
Eines fällt hierbei besonders aus: Das durch den schlechten Scan entstandene Schriftbild behält Acrobat sogar extra bei, obwohl das ursprüngliche Bild des Scans entfernt und durch editierbaren Text ersetzt wurde. Der Blick in die Schriftauswahl zeigt in unserem Beispiel den Schriftnamen *Cambria-9094, wodurch klar wird, dass Acrobat extra die schlechte Qualität unseres Schriftbilds simuliert.
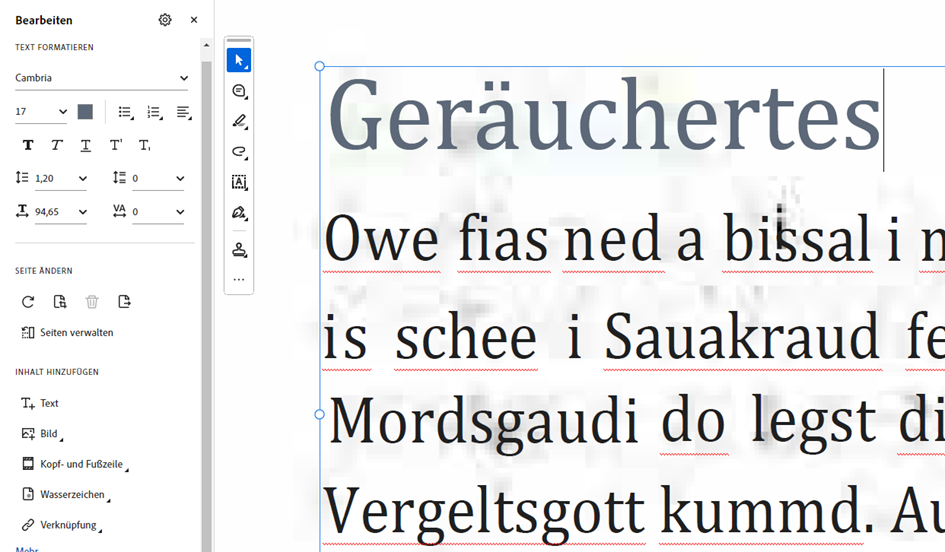
Natürlich können wir bei Bedarf die Schriftart austauschen und so ein neues Schriftbild schaffen.
Fazit:
Für die Archivierung gescannter Dokumente empfiehlt sich die OCR-Texterkennung als durchsuchbares Bild. Dadurch wird die Darstellung der Scanvorlage erhalten und einfach durch die unsichtbare Textschicht die Suchfunktion ermöglicht.
Der Wunsch nach Bearbeitungsmöglichkeiten eines gescannten Dokuments ist inzwischen durch eine entsprechende Einstellung möglich, so dass ein gescanntes Dokument gänzlich editiert werden kann.
In unseren Acrobat Seminaren zeigen wir viele weitere ungeahnte Möglichkeiten der PDF-Bearbeitung. Und wer mit Tungsten (Kofax) Power PDF Advanced arbeitet, wird bei uns genauso fündig.